A Compact C Utilities Library
Since we are now in the 21st century, llib uses C99, but is compatible with MSVC when compiled as C++. This leads to some ‘unnecessary’ casting to keep C++ happy, but working in the intersection between C99 and MSVC C++ makes this library very portable. The features it depends on are the freedom to declare variables in for-loops and variadic preprocessor macros.
It has been tested on Windows 7 64-bit (mingw and MSVC), and both Linux 32-bit and 64-bit.
There are a number of kitchen-sink extended C libraries like glibc and the Apache Portable Runtime but these are big and awkward to use on all platforms. llib aims to be small as possible and intended for static linking with your application (the BSD licensing should help with this).
llib provides a refcounting mechanism, extended string functions, dynamically-resizable arrays, doubly-linked lists and maps using binary trees. The aim of this first release is not to produce the most efficient code possible but to explore the API and validate the refcounting semantics.
Using this basic mechanism will cost your program less than 10Kb; a Linux executable using features from the whole library is less than 40Kb.
A note on style: although C has been heavily influenced by C++ over the years, it remains C. So judicious use of statement macros like FOR is fine, if they are suitably hygenic:
#define FOR(i,n) for (int i = 0, n_ = (n); i < n_; i++)
Reference Counting
llib provides refcounted arrays, which contain their own size. You do not ever use
free on objects created by llib, and instead use obj_unref.
#include <stdio.h> #include <llib/obj.h> int main() { int *ai = array_new(int,10); for (int i = 0, n = array_len(ai); i < n; ++i) ai[i] = 10.0*i; ... obj_unref(ai); return 0; }
C does not have smart pointers, but dumb pointers with hidden secrets. All objects are over-allocated, with a hidden header behind the pointer. This keeps track of its size if it is an array, and there is a type descriptor indexing a type object which contains a ‘destructor’ for the object. Objects start out with a reference count of 1, and the macro obj_ref increments this count; if un-referenced and the count is zero, then we call the destructor and free the memory.
typedef struct ObjHeader_ { unsigned int type:14; unsigned int is_array:1; unsigned int is_ref_container:1; unsigned int _ref:16; unsigned int _len:32; } ObjHeader;
This allows for objects to safely share other objects without having to fully take ownership. Reference counting cuts down on the amount of ‘defensive copying’ needed in typical code.
Unless you specifically define LLIB_NO_REF_ABBREV, the basic operations are aliased as
ref and unref; there is also an alias dispose for obj_unref_v which
un-references multiple objects.
It is straightforward to create new objects which fit with llib’s object scheme:
typedef struct { int *ages; } Bonzo; static void Bonzo_dispose(Bonzo *self) { printf("disposing Bonzo\n"); unref(self->ages); } Bonzo *Bonzo_new(int *ages) { Bonzo *self = obj_new(Bonzo,Bonzo_dispose); self->ages = ref(ages); return self; } void test_bonzo() { int AGES[] = {45,42,30,16,17}; int *ages = array_new(int,5); FOR(i,5) ages[i] = AGES[i]; //?? Bonzo *b = Bonzo_new(ages); unref(ages); printf("%d %d\n",b->ages[0],b->ages[1]); unref(b); }
There is nothing special about such structures; when creating them with the macro
obj_new you can provide a dispose function. In this case, Bonzo objects
reference the array of ages, and they un-reference this array when they are finally
disposed. The test function releases the array ages, and thereafter the only
reference to ages is kept within the struct.
Arrays can be reference containers which hold refcounted objects:
Bonzo *dogs = array_new_ref(Bonzo,3);
// see? They all happily share the same ages array!
dogs[0] = Bonzo_new(ages);
dogs[1] = Bonzo_new(ages);
dogs[2] = Bonzo_new(ages);
...
// this un-references the Bonzo objects
// only then the array will die
unref(dogs);
Sequences
llib provides resizable arrays, called ‘seqs’.
float **s = seq_new(float); seq_add(s,1.2); seq_add(s,5.2); .... float *arr = ref(*s); unref(s); // array still lives! FOR(i,array_len(arr)) printf("%f ",arr[i]); printf("\n"); // alternative macro // FOR_ARR(float,pf,arr) printf("%f ",*pf);
You treat seqs like a pointer to an array, and use seq_add to ensure that the
array is resized when needed. *s is always a valid llib array, and in particular
array_len returns the correct size.
A seq keeps a reference to this array, and to get a reference to the array you
can just say ref(*s) and then it’s fine to dispose of the seq itself. The function
seq_array_ref combines these two operations of sharing the array and disposing
the seq, plus resizing to fit.
These can also explicitly be reference containers which derereference their objects afterwards if you create them using seq_new_ref.
Linked Lists
A doubly-linked list is a very useful data structure which offers fast insertion at arbitrary posiitions. It is sufficiently simple that it is continuously reinvented, which is one of the endemic C diseases.
List *l = list_new_str();
list_add (l,"two");
list_add (l,"three");
list_insert_front(l,"one");
printf("size %d 2nd is '%s'\n",list_size(l),list_get(l,1));
FOR_LIST(pli, l)
printf("'%s' ",pli->data);
printf("\n");
unref(l);
printf("remaining %d\n",obj_kount());
return 0;
// size 3 2nd is 'two'
// 'one' 'two' 'three'
// remaining 0
A list of strings is a ref container, but with the added thing that if we try to add a string which is not one of ours then a proper refcounted copy is made. So it is safe to add strings from any source, such as a local buffer on the heap. These are all properly disposed of with the list.
Generally, containers in C are annoying, because of the need for typecasts. (Already
with -Wall GCC is giving us some warnings about those printf flags.) Integer
types can fit into the pointer payload fine enough, but it isn’t possible to
directly insert floating-point numbers. List wrappers do a certain amount of pointer
aliasing magic for us:
float ** pw = (float**)listw_new();
listw_add(pw, 10);
listw_add(pw, 20);
listw_add(pw, 30);
listw_add(pw, 40);
listw_insert(pw, listw_first(pw), 5);
printf("first %f\n",listw_get(pw,0));
FOR_LISTW(p, pw)
printf("%f\n",**pw);
They are declared as if they were seqs (pointers to arrays) and there’s a way to iterate over typed values.
Generally I've found that sequences are easier to use (and much more efficient to iterate over) unless there are many insertions in the middle.
Maps
Maps may have two kinds of keys; integer/pointer, and strings. Like string lists, the latter own their key strings and they will be safely disposed of later. They may contain integer/pointer values, or string values. The difference again is with the special semantics needed to own arbitrary strings.
Typecasting is again irritating, so there are macros map_puti etc for the common integer-valued case:
Map *m = map_new_str_ptr();
map_puti(m,"hello",23);
map_puti(m,"alice",10);
map_puti(m,"frodo",2353);
printf("lookup %d\n",map_geti(m,"alice"));
map_remove(m,"alice");
FOR_MAP(mi,m)
printf("key %s value %d\n",mi->key,mi->value);
unref(m);
The implementation in llib is a binary tree – not in general the best, but it works reliably and has defined iteration order.
Maps can be initialized from arrays of MapkeyValue structs. Afterwards, such an
array can be generated using map_to_array:
MapKeyValue mk[] = {
{"alpha","A"},
{"beta","B"},
{"gamma","C"},
{NULL,NULL}
};
Map *m = map_new_str_str();
map_put_keyvalues(m,mk);
MapKeyValue *pkv = map_to_array(m);
for (MapKeyValue *p = pkv; p->key; ++p)
printf("%s='%s' ",p->key,p->value);
printf("\n");
unref(m);
unref(pkv);
llib also provides ‘simple maps’ which are arrays of strings where the even elements are the keys and the odd elements are the values; str_lookup will look up these values by linear search, which is efficient enough for small arrays. smap_new creates a sequence so that smap_put and smap_get do linear lookup; smap_add simply adds a pair which can be more efficient for bulk operations.
Interfaces
Sometimes we are not interested in the particular implementation, only in the abstract functionality.
For instance, arrays, lists and maps can all be iterated over, and maps are indexable. This idea was
popularized by Java, and the llib concept is similar. List and Map support the Iterable
interface:
#include <llib/interface.h"
...
List *ls = list_new_str();
list_add(ls, "ein");
list_add(ls, "zwei");
list_add(ls, "drei");
Iterator *it = interface_get_iterator(ls);
char *s;
while (it->next(it,&s)) {
printf("got '%s'\n",s);
}
unref(it);
There is an optional function nextpair in the Iterator struct, which grabs key/value
pairs:
Map *m = map_new_str_str();
map_put(m,"one","1");
map_put(m,"two","2");
map_put(m,"three","3");
Iterator *it = interface_get_iterator(m);
char *key, *val;
while (it->nextpair(it,&key,&val)) {
printf("'%s': '%s'\n",key,val);
}
next is also defined for Map – it returns the keys – but a non-NULL nextpair means we have
an associative array.
Naturally C does not provide us with any special syntactical sugar, especially to create ‘objects’
that implement interfaces. Here is a simple example – how to create a Stringer interface.
It always provides tostring, but may also provide parse.
typedef struct { char* (*tostring) (void *o); void* (*parse) (const char *s); // optional } Stringer; .... // register the interface type obj_new_type(Stringer,NULL); // implement tostring for Lists static char* list_tostring(void *o) { return str_fmt("List[%d]",list_size((List*)o)); } static Stringer s_list = { list_tostring, NULL // we can choose not to implement parse }; .... // List implements Stringer interface_add(interface_typeof(Stringer), interface_typeof(List), &s_list);
Here is how ‘simple maps’ implement Iterable:
typedef struct ArrayIter_ ArrayIter; struct ArrayIter_ { // Iterable bool (*next)(ArrayIter *ai, void *pval); bool (*nextpair)(ArrayIter *iter, void *pkey, void *pval); int len; // private implementation int n; void **P; }; // over key/value values of simple maps static bool smap_nextpair(ArrayIterator *ai, void *pkey, void *pval) { if (ai->n == 0) return false; ai->n -= 2; *((void**)pkey) = *(ai->P)++; *((void**)pval) = *(ai->P)++; return true; } // over keys of simple maps static bool smap_next(ArrayIter *ai, void *pval) { void *val; return smap_nextpair(ai,pval,&val); } static Iterator* smap_init (const void *o) { ArrayIter *ai = obj_new(ArrayIter,NULL); ai->n = array_len(o); ai->P = o; ai->next = smap_next; ai->nextpair = smap_nextpair; ai->len = array_len(o)/2; return (Iterator*)ai; } static Iterable smap_i = { smap_init }; ... t_iterable = obj_new_type(Iterable,NULL); interface_add(t_iterable,OBJ_KEYVALUE_T,&smap_i);
Although the original concept only applies to functions (methods), these interfaces are defined by structs that may contain arbitrary data, perhaps without any functions. You can think of them as a general mechanism for attaching extra information to a type, which is indexed by the type of that information.
Array Operation Macros
C is not good at expressing generic algorithms, so we have to use the preprocessor.
By inlining the expression we side-step the lack of anonymous functions in C
Consider the FINDA macro;
it declares an index and sets it to the next array position that matches the expression.
A placeholder variable _ is set in turn to each value from the array.
The array must be ‘one of ours’ – that is, array_len(a) is meaningful.
(FINDZ is a similar animal which iterates until the end of a NULL-terminated array.)
#include <llib/array.h>
....
int nums[] = {-1,-2,2,-1,4,3};
int *arr = array_new_init(int,nums);
int k = 0;
while (true) {
FINDA(i,arr,k, _ > 0);
if (i == -1)
break;
printf("non-zero at %d is %d\n",i,arr[i]);
k = i + 1;
}
MAPA likewise declares a new variable, which is a new array created by applying an expression to elements of a source array. The MAPAR variant is similar but forces the result to be a reference container:
char** ss = str_strings("one","two","three",NULL);
MAPA(int,ssl,strlen(_),ss);
assert(ssl[0] == 3);
assert(ssl[1] == 3);
assert(ssl[2] == 5);
int nn[] = {1,2,22,1,40,3};
int *na = array_new_init(int,nn);
MAPAR(char*,sna,str_fmt("%02d",_),na);
assert(str_eq(str_concat(sna," "),"01 02 22 01 40 03"));
In FILTA the expression determines whether the value will be collected in the output array.
So given the array na above, then FILTA(int,nas,na, _ < 10) results in nas == {1,2,1,3}.
In C99 mode these macros use __typeof which is a GNU extension supported by Clang and Intel,
and in C++11 mode uses decltype.
Strings
Strings are the usual nul-terminated char arrays, but llib refcounted strings are arrays and so
already know their size through array_len (which will be faster than strlen for long strings.)
It’s generally hard to know portably if an arbitrary pointer is heap-allocated, so there’s
str_ref which does the ‘one of mine?’ check and makes a refcounted copy if not, otherwise acts
just like obj_ref.
str_fmt is a convenient and safe way to do sprintf, and will return a refcounted string.
String support in C is famously minimalistic, so llib adds some extensions. str_split uses a delimiter to split a string into an array using delimiter chars. The array is a ref container so the strings will be disposed with it:
Str* words = str_split("alpha, beta, gamma",", ");
assert(array_len(words) == 3);
assert(str_eq(words[0],"alpha"));
assert(str_eq(words[1],"beta"));
assert(str_eq(words[2],"gamma"));
unref(words);
Building up strings is a common need, and llib provides two ways to do it. If you already have
an array of strings then feed it to str_concat with a delimiter – it is the inverse operation
to str_split. If the string is built up in an ad-hoc fashion then use the strbuf_* functions.
A string buffer is basically a sequence, so that strbuf_add is exactly the same as seq_add
for character arrays. strbuf_adds appends a string, and strbuf_addf is equivalent to
strbuf_adds(ss,str_fmt(fmt,…)).
They are used for operations which modify strings, like inserting, removing and replacing, and
resemble the similar methods of C++’s std::string.
Then there are operations on strings which don’t modify them:
const char *S = "hello dolly";
int p = str_findstr(S,"doll");
assert(p == 6);
p = str_findch(S,'d');
assert(p == 6);
p = str_find_first_of("hello dolly"," ");
assert(p == 5);
assert(str_starts_with(S,"hell"));
assert(str_ends_with(S,"dolly"));
They're simple wrappers over the old strchr, strstr etc functions that return offsets
rather than pointers. This is a more appropriate style for refcounted strings where you
want to only use the allocated ‘root’ pointer.
String Templates
These are strings where occurences of a $(var) pattern are expanded. Sometimes called
‘string interpolation’, it’s a good way to generate large documents like HTML output and does not
suffer from the format string size limitations of the printf family.
You make a template object from a template string, and expand a template using that
object plus a function to map string keys to values, and a ‘map’ object.
The default form assumes that the object is just a NULL-terminated array of strings listing the keys
and values, and plain linear lookup.
const char *tpl = "Hello $(name), how is $(home)?";
char *tbl1[] = {"name","Dolly","home","here",NULL};
StrTempl st = str_templ_new(tpl,NULL);
char *S = str_templ_subst(st,tbl1);
assert(str_eq(S,"Hello Dolly, how is here?"));
You don’t have to use $() as the magic characters, which is the default indicated by NULL in
str_templ_new. For instance, if expanding templates containing JavaScript it’s better to use @()
which will not conflict with use of JQuery.
We can easily use a llib map with the more general form:
Map *m = map_new_str_str();
map_put(m,"name","Monique");
map_put(m,"home","Paris");
S = str_templ_subst_using(st, (StrLookup)map_get, m);
assert(str_eq(S,"Hello Monique, how is Paris?"));
String interpolation is more common in dynamic languages, but perfectly possible to do in less
flexible static languages like C, as long as there is some mechanism available for string lookup.
You can even use getenv to expand environment variables, but it does not quite have the
right signature. Generally if any lookup fails, the replacement is the empty string.
static char *l_getenv (void *data, char *key) { return getenv(key); } void using_environment() { StrTempl st = str_templ_new("hello @<USER>, here is @<HOME>","@<>"); char *S = str_templ_subst_using(st, (StrLookup)l_getenv, NULL); printf("got '%s'\n",S); dispose(st,S); }
A powerful feature is the ability to define subtemplates. Say we have the following template:
<h2>$(title)</h2> <ul> $(for items | <li><a src="$(url)">$(title)</a></li> |) </ul>
Then items must be something iterable returning something indexable, in other words,
the object must implement the Iterable interface. Templates were the original
motivation for the the interface abstraction; the original implementation was tightly coupled
to llib List and Map. Now the code is dynamically coupled to any types which implement
Iterable and Accessor and is smaller and more flexible.
The text inside “|…|” is the subtemplate and any variable expansion inside it will look up names in the objects returned by the iteration. One way to create suitable data would be:
char ***smap = array_new_ref(char**,2); smap[0] = str_strings("title","Index","url","catalog.html",NULL); smap[1] = str_strings("title","home","url","index.html",NULL); char *tbl = { "title", "Pages", "items",(char*)smap, NULL };
Setting up this kind of data is a bit clumsy, but in the next section I'll show some convenient macros for building dynamic data structures in code.
Values
llib values have dynamic types since they have their type encoded in their headers.
A value can be an array of ints, a string, or a map of other values, and so forth, and
its type and structure can be inspected at run-time.
To represent numbers we have to introduce wrappers for integer, double and boolean
types, rather as it is done in Java. This being C, the programmer has to explicitly box floats
(for example) using value_float and so forth, and unbox with value_as_float.
Ref-counted strings are llib values, although string literals need an explicit str_new.
The typedef PValue is just void*. There is a special type ‘error’, so using values is a
flexible way for a C function to return a sensible error message.
PValue v = my_function(); if (value_is_error(v)) { fprintf(stderr,"my_function() is borked: %s\n",(char*)v); } else { // we're cool double res = value_as_float(v); ... }
Note that an error value is just a ref-counted string, with a distinct type. llib types are distinct
if they have different names, so the trick is to define a standard type slot OBJ_ECHAR_T
where the type name is “echar_ *” and then make an error like so:
PValue value_error (const char *msg) { PValue v = str_new(msg); obj_set_type(v,OBJ_ECHAR_T); return v; }
(my_function could actually return floats, arrays, ad absurdum and the caller could
distinguish between these using the value_is_xxx functions. But this is not a good idea
in general and causes confusion even with dynamic languages.)
With values, you can have the same kind of dynamic ad-hoc data structures that are common in dynamic languages. For instance, this is a neater way to specify the data for the HTML template just discussed:
PValue v = VM(
"title",VS("Pages"),
"items",VA(
VMS("url","index.html","title","Home"),
VMS("url","catalog.html","title","Links")
)
);
This uses llib’s JSON support, which works very naturally with values. (If you find
these shorthand macros clobbering your stuff, then define LLIB_NO_VALUE_ABBREV
before including ‘<llib/json.h>’. ) JSON itself is a
great notation to express dynamic data structures (although many people find the
ad-hoc part less of a solution and more of a problem):
const char *js = "{'title':'Pages','items':[{'url':'index.html','title':'Home'},"
"{'url':'catalog.html','title':'Links'}]}";
....
v = json_parse_string(js);
S = str_templ_subst_values(st,v);
Another useful property of values when used in templates is that they know how
to turn themselves into a string. With plain data, we have to assume that the
expansions result in a string,
but if they do result in a value, then value_tostring will be used. (The template function
$(i var) will explicitly convert integers to strings, but it’s hard to work with
floating-point numbers this way).
Object Pools
C++ users are fond of RAII – Resource Acquision Is Initialization. The
language guarantees that destructors of locally scoped objects will be called, however you
exit from that scope. So (for instance) a ifstream will be automatically closed when
no longer needed.
I've tried to escape from the shadow of C++ envy in llib, but this is indeed a convenient pattern. All llib objects can have a dispose operation, which will be called when their ref count goes to zero. In C++ terminology, llib objects have virtual destructors. An alternative way to open files is provided:
FILE **pf = file_fopen(file,"r"); if (value_is_error(pf)) { fprintf(stderr,"can't open file %s\n",value_as_string(pf)); return false; } char *first = file_getline(*pf); .... unref(pf); return true;
Here disposing of the file object closes the underlying stream. This by itself is not spectacular.
If the function has several exit points, then we have to remember to unref the file each time
(there’s already a leaking error object when we can’t open the file). A common
strategy in C is to goto the end and do all the cleanup there.
GCC provides a useful extension; the cleanup attribute. You provide a function which will be automatically called to clean up a variable marked with this attribute. This extension continues to be supported by Clang and Intel, so it’s not a bad option, if you can live outside the strict C99 standard. llib hides this as scoped:
void do_something (const char *file) { scoped FILE **pf = file_fopen(file,"r"); .... // magic disposal of pf! }
However you leave do_something, the file will be the closed. The power of the approach
comes from llib objects all knowing dynamically how to dispose themselves (“virtual destructors”)
The cool thing about llib reference counting semantics is that if a container is disposed, it will unref all the objects it contains. Complicated dynamic data structures (read from a JSON or XML file, say) can be completely cleaned up, while allowing for sharing. The key point is that every object needs a parent. Orphan objects are bad news because they will never be unref'd. Object Pools define a default reference container for all objects created in their scope.
{
scoped void *P_ = obj_pool();
// do whatever you like, create orphans;
// they will all be automatically disposed!
}
It’s better to use the macro scoped_pool; it’s shorter, and has an alternative C++
implementation which llib uses to support that old elephant, MVSC.
The main rule is that any object returned from a function must have its reference count incremented, so that pool cleanup doesn’t dispose that object prematurely.
Object pools can be nested (implemented as a stack of resizable array ref containers). There is some overhead involved, but sometimes lazy is the best way; in my experience it can take a fair amount of work to write leak-proof llib code.
File Operations
llib deals with a few irritations about <stdio.h> . For instance file_gets is like fgets
except that it strips off any offending end-of-line characters (“\n” or “\r\n”). With
file_getline you get a refcounted string allocated (up to LINESIZE which is defined as 512
characters). file_getlines will return the whole of a stream as an array of strings. Or you
can just use file_read_all to grab the contents of a file path.
Calling commands and collecting the result is a common operation, and file_command will grab the first line of output. Standard error is redirected, so you can check any error messages. file_command_lines gets all of a command’s output as an array of strings.
There is file_exists (true or false) and the interesting file_exists_any, where the
first file that’s accessible is returned, NULL otherwise. This compensates for the lack
of an or-operation which returns non-boolean results, which is so useful in languages
like Perl and Lua.
There are a set of functions for manipulating file paths, that don’t have the gotchas of the POSIX functions; they can be split using file_basename, file_dirname and file_extension; file_replace_extension is often useful, and file_expand_user will conviently replace an initial ‘~’ with the user’s home directory. All of these functions return properly ref-counted objects.
XML
This is a large and opinionated subject, so let me state that what most people need is ‘pointy-bracket data language’ (PBDL) rather than full-blown schemas-and-transforms (XML). In particular, it is a common configuration format. When used in that way, we can simplify life by ignoring empty text elements and comments – since it is the structure of the data that is important. If test.xml is:
<root>
<item name='age' type='int'>10</item>
<item name='name' type='string'>Bonzo</item>
</root>
then xml_parse_file("test.xml",true) will return a root element with two item child elements.
The representation is a little unusual but straightforward; an element is an array of objects,
with the first item being the tag name, the second (optional) item being an array of atributes
(so-called ‘simple map’) and the remainder contains the child nodes – these are either strings or
elements themselves. So test.xml is completely equivalent to this data constructor:
v = VAS("root",
VAS("item",VMS("name","age","type","int"),"10"),
VAS("item",VMS("name","name","type","string"),"Bonzo")
);
and the output with json_tostring is
["root",["item",{"name":"age","type":"int"},"10"],["item",{"name":"name","type":"string"},"Bonzo"]]
Tabular Data
The table_* functions work with files containing rows of data separated by a delimiter, either
space or commas. These files may have a initial header containing field names. A novel aspect
of llib table support is that you can ask for columns to be generated and converted.
Assume we have a simple CSV file like so:
Name,Age Bonzo,12 Alice,16 Frodo,46 Bilbo,144 ..... Table *t = table_new_from_file("test.csv", TableCsv | TableColumns | TableAll); char **titles = t->col_names; // {"Name","Age"} char **first = t->rows[0]; // {"Bonzo","12"} float *ages = (float*)t->cols[1]; // {12,16,46,144}
The TableCsv option implies TableComma and TableColumnNames (first line is field names); TableAll means that all of the file is to be read immediately, and TableColumns means that
columns are to be constructed.
This constructor, and its relative table_new_from_stream, will always return a Table object;
if the error field is non-NULL, then it describes the error.
By default, if a column appears to be numerical, it is converted to floats. It’s possible to have more control over this by explicitly specifying the conversion to be used for each column:
Table *t = table_new_from_file(file, TableCsv | TableAll);
if (t->error) {
fprintf(stderr,"%s\n",t->error);
return 1;
}
table_convert_cols(t,0,TableString,1,TableInt,-1);
table_generate_columns(t);
int *ages = (int*)t->cols[1]; // {12,16,46,144}
When done explicitly, only the columns specified will be constructed.
Normally data is read from a stdio stream, but table_add_row can be used to construct
a table from other data sources. This has the correct signature to be used with the Sqlite
C API’s sqlite3_exec function:
int err;
sqlite3 *conn;
char *errmsg;
err = sqlite3_open("test.sl3",&conn);
Table *t = table_new(TableCsv | TableColumns);
err = sqlite3_exec(conn,"select * from test",
table_add_row,t,&errmsg);
if (err) {
printf("err '%s'\n",errmsg);
return 1;
}
table_finish_rows(t);
Command-line Parsing
There are standard ways of processing command-line arguments in POSIX, but they're fairly primitive and not available directly on Windows. The arg module gives a higher-level way of specifying arguments, which allows you to bind C variables to named flags and arguments. Here is a modified head-like utility:
// cmd.c #include <stdio.h> #include <llib/arg.h> int lines; FILE *file; bool print_lines; PValue args[] = { "// cmd: show n lines from top of a file", "int lines=10; // -n number of lines to print",&lines, "bool verbose=false; // -v controls verbosity",&verbose, "bool lineno; // -l output line numbers",&print_lines, "infile #1=stdin; // file to dump",&file, NULL }; int main(int argc, const char **argv) { args_command_line(args,argv); char buff[512]; int i = 1; while (fgets(buff,sizeof(buff),file)) { if (print_lines) printf("%03d\t%s",i,buff); else printf("%s",buff); if (i++ == lines) break; } fclose(file); return 0; }
Default help output:
cmd: show n lines from top of a file
Flags:
--help,-h help on commands and flags
--lines,-n (10) number of lines to print
--verbose,-v (false) controls verbosity
--lineno,-l (false) output line numbers
--#1 (stdin) file to dump
This was inspired by the lapp framework for Lua;
one specifies the arguments in
a way that they can be used both for printing out help automatically and with enough
type information that values can be parsed correctly. So cmd -l x is an error
because ‘x’ is not a valid integer; cmd temp.txt is an error if temp.txt cannot
be opened for reading. So we keep the logic of the program as straightforward as
possible; note how the type and default value is specified using pseudo-C notation
(the default value for a boolean flag is false but can be set to true.)
Otherwise, the flag parsing is GNU style, with long flags using ‘—’ and short aliases with ‘–’. Short flags can be combined ‘-abc’ and their values can follow immediately after ‘-I/usr/include/lua’. The long flag name comes from the specified name, and the short flag is optionally specified after the start of the help comment. Names begining with ‘#’ are special and refer to the non-flag arguments of a program.
A flag specifier like string include[] binds to an array of strings (char**);
repeated invocations will add to this array (e.g “-I/mylib -I..”).
However, if specified like so “int arr[]=,”, then the flag takes a single
argument which is a list of integers separated by ‘,’. You can use any delimiter, but
remember that some characters have special meaning in the shell, so ‘|’ and ‘;’ are not a
good idea.
A default for an array flag cannot be specified; if the flag is not present the variable is initialized to a array of zero length. llib arrays know their size, so we don’t have to track this separately.
The understood types are int, float (means double), string (ref-counted char),
bool, infile and outfile. The last two bind to FILE and will try to open the file
for you; their defaults can be stdin and stdout respectively.
Flags can also be implemented by functions, which you can see in action in
examples/testa.c. Commands are related, where a program exposes its functionality with
subcommands. for instance ‘git status’. testa shows how a simple but effective
interactive prompt can be produced by spliting the line and parsing it explicitly.
Since llib is linked statically by default, the resulting programs remain small;
cmd is only 22Kb on a 32-bit Linux system.
Example: Generating plots with Flot
Cross-platform graphics capabilities are not easily available to simple C programs. The ‘old-skool’ approach is for your program to write out data in a suitable form for GnuPlot, or as CSV to be fed into Excel (on Windows). But modern browsers offer very capable graphics, and client-side libraries like Flot use this to produce good-looking plots – ‘client-side’ because they take data and options in JSON form and render it on the browser.
llib can generate JSON, and it can expand templates – this is all we need to write suitable HTML for Flot to render. By default, I've chosen to let this HTML grab the required JavaScript libraries from the Net, although this isn’t a big problem in practice since browsers will cache frequently-downloaded scripts. (You can always unzip Flot somewhere and arrange for the HTML to point to that location.)
Doing simple plots is straightforward (go to examples/flot/'):
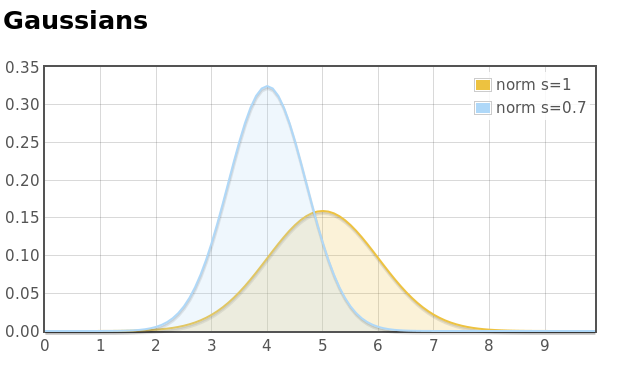
// flot-norm.c #include "flot.c" double sqr(double x) { return x*x; } double *make_gaussian(double m, double x, double *xv) { double s2 = 2*sqr(x); double norm = 1.0/(M_PI*s2); int n = array_len(xv); double *res = array_new(double,n); FOR (i,n) { res[i] = norm*exp(-sqr(xv[i]-m)/s2); } return res; } int main() { Flot *P = flot_new("caption", "Gaussians"); double *xv = farr_range(0,10,0.1); flot_series_new(P,xv,make_gaussian(5,1,xv), FlotLines,"label","norm s=1"); flot_series_new(P,xv,make_gaussian(4,0.7,xv), FlotLines,"label","norm s=0.7"); flot_render("norm"); return 0; }
Once a Flot object is created, then series can be added; these are fed separate
X and Y data as llib arrays of double values – these know how large they are, so we
don’t need to pass an explicit size. farr_range is useful for generating X values
sampled with a delta.
The result is indeed good-looking (the meaning of ‘flot’ in Danish) and by default a legend is generated.
This Flot API is designed to correspond as closely as possible with the original
API. According to Customizing the Data Series
the option to fill the area between the line and the axis is series:{lines:{fill:A}}
where A is the alpha value to apply to the line colour. This can be expressed
like so:
Flot *P = flot_new("caption", "Gaussians","series.lines.fill",VF(0.2));
That is, the arguments passed to flot_new pass directly into the options of
the Flot plot object. These options consist of a key followed by its data; the key
may be dotted to express the nested maps which are natural in JavaScript but
awkward to express in C. The data needs to be escaped explicitly as a value_float.
The result is particularly good-looking:
When using statically-declared data, you must make a llib array – the farr_copy macro is useful here. Note that series also have options; when specifying a fill, note that it’s just “lines.fill”, not “series.lines.fill” used for the plot-wide option.
// apply gradient from top to bottom as background, and move legend
Flot *P = flot_new("caption", "First Test",
"grid.backgroundColor",flot_gradient("#FFF","#EEE"),
// 'nw' is short for North West, i.e. top-left
"legend.position","nw"
);
// Series data must be llib arrays of doubles
double X[] = {1,2,3,4,5};
double Y1[] = {10,15,23,29,31};
double Y2[] = {9.0,9.0,25.0,28.0,32.0};
double *xv = farr_copy(X);
double *yv1 = farr_copy(Y1), *yv2 = farr_copy(Y2);
// fill underneath this series
flot_series_new(P,xv,yv1, FlotLines,"label","cats",
"lines.fill",VF(0.2) // specified as an alpha to be applied to line colour
);
// override point colour
flot_series_new(P,xv,yv2, FlotPoints,"label","dogs","color","#F00");
// will generate test.html
flot_render("test");
Again, you can look at the grid options when specifying grid options; same for legend options.
If the Y data is NULL, then it’s assumed that the X data array has both x and y
values, as even and odd entries respectively. This is particularly convenient
when building up data using sequences and is reminiscent of how you would do
this in JavaScript using push:
double **vsin = seq_new(double);
double **vcos = seq_new(double);
for (double x = 0; x < 2*M_PI; x += 0.1) {
seq_add2(vsin,x,sin(x));
seq_add2(vcos,x,cos(x));
}
flot_series_new(P,farr_seq(vsin), NULL,FlotLines,"label","sine");
flot_series_new(P,farr_seq(vcos), NULL,FlotLines,"label","cosine");
To help displaying data from the table module, farr_sample_float and farr_sample_int can be used to convert the float and int column arrays generated by table:
void read_dates_and_values(const char *file, farr_t *dates, farr_t *values) { Table *t = table_new_from_file(file, TableCsv | TableAll); if (t->error) { fprintf(stderr,"%s %s\n",file,t->error); exit(1); } table_convert_cols(t,0,TableInt,1,TableFloat,-1); table_generate_columns(t); *dates = farr_sample_int((int*)t->cols[0],0,-1,1); *values = farr_sample_float((float*)t->cols[1],0,-1,1); }
These helpers create slices-with-steps of arrays (there’s also farr_sample for
working with double* arrays.) and work like Python slices; -1 means “the last element”.
In summary, this example C implementation of a JavaScript API is intended to make it easier for C programmers to make decent plots of their data for casual consumption. For publication-ready output, you need another solution, but this allows you to quickly see what your calculations look like and avoids the tedious need for preparing data for another tool. It shows that C is quite capable of operating with dynamic data, if certain simple rules are followed.